Build Recommender System with LLM-based Reranker
Build Recommender System with LLM-based Reranker
Gorse implemented visual recommendation flow editor and LLM-based reranker during versions v0.5.2 to v0.5.5. This article introduces how to combine these two features to create a recommendation flow that uses an LLM-based reranker via the RecFlow editor.
Preparation
First, you need to prepare a reranker service compatible with the Jina reranking API. This article uses the reranking service provided by Alibaba Cloud DashScope as an example.
If you have already deployed the Gorse recommender system, you need to add the API endpoint, API key, and model name to the following fields in the configuration file:
[recommend.ranker.reranker_api]
# URL for the reranker API, supports Jina style.
url = "https://dashscope.aliyuncs.com/compatible-api/v1/reranks"
# Auth token for the reranker API.
auth_token = "RERANKER_API_KEY"
# The reranker model.
model = "qwen3-rerank"You can also override these fields via environment variables:
GORSE_RERANKER_URL="https://dashscope.aliyuncs.com/compatible-api/v1/reranks"
GORSE_RERANKER_AUTH_TOKEN="RERANKER_API_KEY"
GORSE_RERANKER_MODEL="qwen3-rerank"If you haven't deployed Gorse yet, don't worry. You can start a temporary Gorse instance to experience these features:
docker run -p 8088:8088 \
-e GORSE_RERANKER_URL="https://dashscope.aliyuncs.com/compatible-api/v1/reranks" \
-e GORSE_RERANKER_AUTH_TOKEN="RERANKER_API_KEY" \
-e GORSE_RERANKER_MODEL="qwen3-rerank" \
zhenghaoz/gorse-in-one --playgroundRecFlow Editor
Open the dashboard (default port 8088), click RecFlow in the left navigation bar to enter the RecFlow editor:
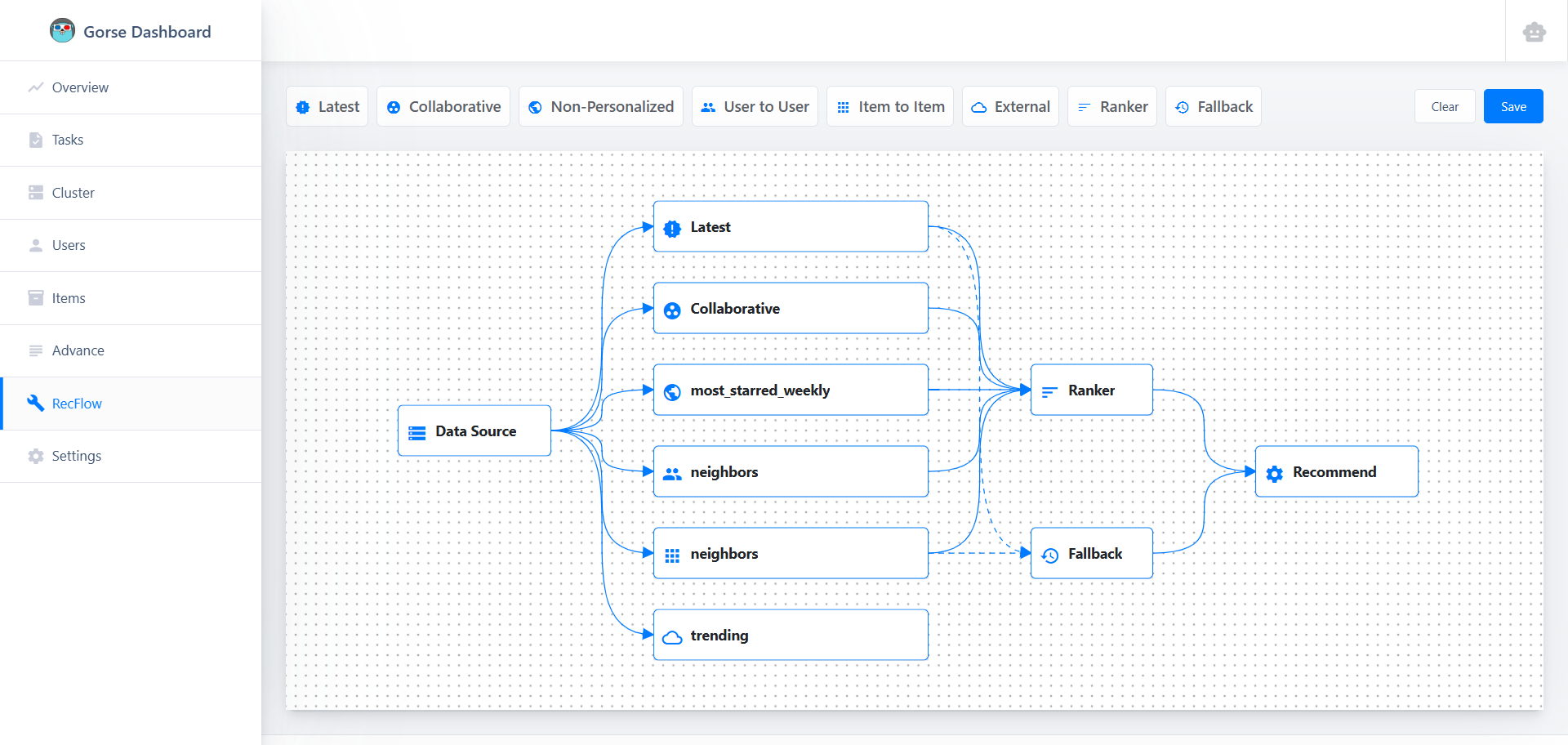
The starting point of the recommendation flow is the Data Source node, and the end point is the Recommend node. For detailed node introductions, please refer to the RecFlow documentation. In this article, we only care about the LLM-based Ranker node. Due to context length limitations, LLMs cannot rank all items, so first, candidate items must be collected by multiple recommenders (such as collaborative filtering, item-to-item, etc.). These candidate items are merged and then sorted by the Ranker node.
Double-click the Ranker node, select the type as LLM, and you will see the LLM-based reranker configuration interface:
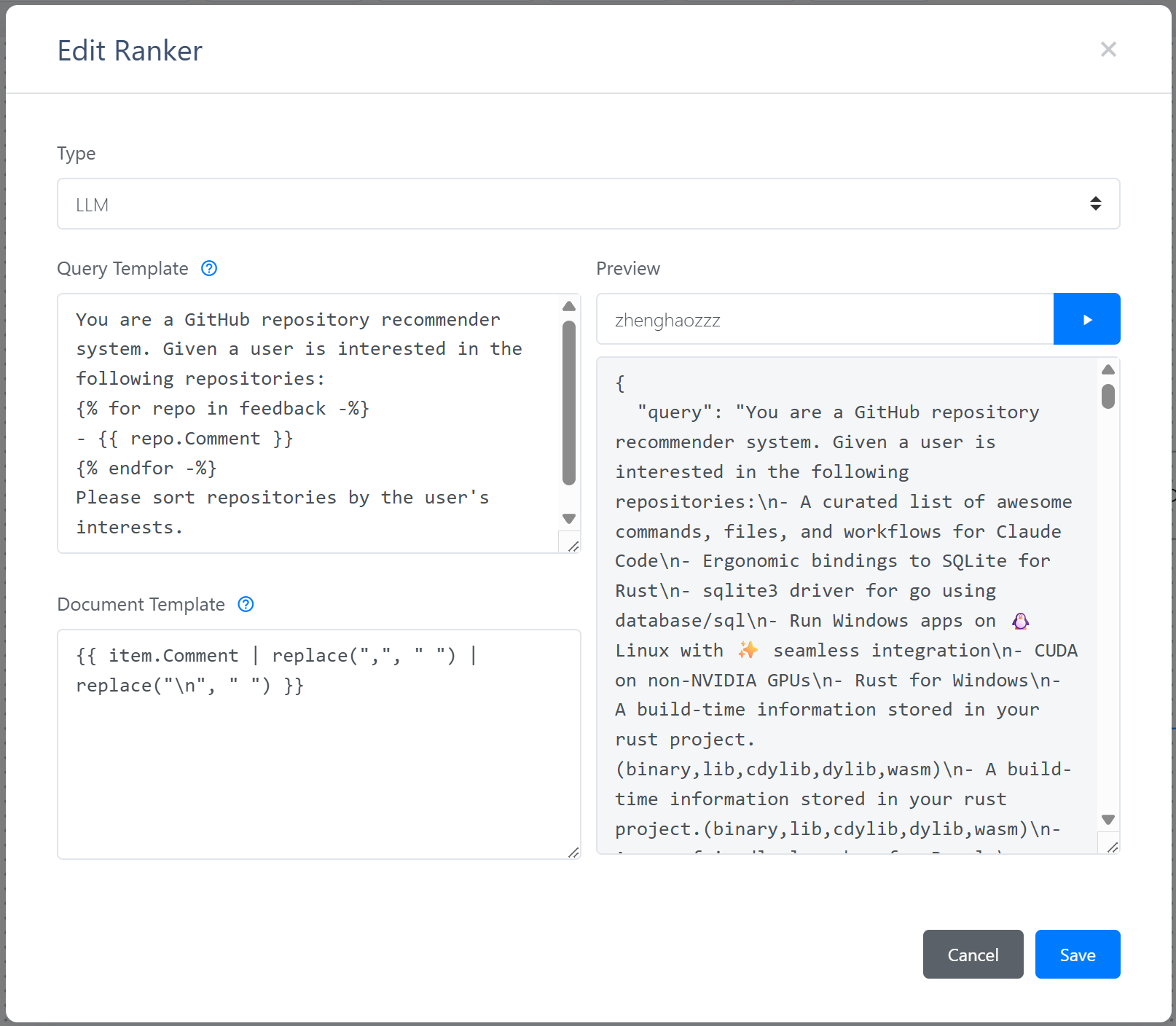
LLM-based reranker requires a query template and a document template. It uses historical feedback and candidate items to render the Jinja2 template, and then sends the rendered content to the reranker API. After entering a user ID and clicking the run button, the dashboard will read the user's recent feedback and the latest items, and use the templates to render the content sent to the reranker API.
After saving the recommendation flow, Gorse will load the recommendation flow defined by the RecFlow editor instead of the one in the configuration file. Fallback nodes are particularly important for LLM-based reranker. When the reranker cannot provide ranking services, Gorse will use the recommendation from the fallback node.
Evaluation
The accuracy of the LLM-based reranker needs to be evaluated using the gorse-bench tool.
- Compile gorse-bench from Gorse repository.
- gorse-bench temporarily does not support recommendation flows defined by the RecFlow editor, so the recommendation workflow configuration needs to be written into the configuration file. Additionally, database access methods also need to be provided via the configuration file or environment variables.
- Run the following command to evaluate the performance of an LLM-based reranker:
./gorse-bench llm --config config.tomlThis tool will read the user's historical feedback and split the feedback into training and test sets in an 8:2 ratio. For each user, the query is rendered using positive feedback from the training set, and documents are rendered using feedback from the test set (including both positive and negative feedback). Finally, Group AUC (GAUC)[1] is used to calculate the ranking accuracy:
where is the AUC for user , and is the number of test set feedbacks for user .
There are not many open-source reranking models available. In this article, we chose the most advanced Qwen3-Reranker model for evaluation and compared it with Factorization Machines (FM) using the playground dataset. To observe the performance of the LLM-based reranker under different numbers of training samples, we divided users into five groups according to the number of training feedbacks and calculated the GAUC for each group:
The experimental results show:
- Reranker models have a significant advantage in cold-start scenarios: When the number of samples is small, Qwen3-Reranker-8B performs better than the FM model, indicating that specifically trained reranker models can effectively improve cold-start performance.
- Traditional models perform better as data accumulates: As the amount of training data increases, the GAUC of the FM model steadily improves and eventually surpasses the reranker model. This shows that traditional models trained on specific data remain very powerful when data is sufficient.
- Model scale has a direct impact on effectiveness: Qwen3-Reranker-8B outperforms its 4B and 0.6B versions in most cases, indicating that model scale is crucial for improving reranking quality.
Future Work
This article is only a preliminary exploration of LLM-based reranking. We will subsequently test more models with a richer set of metrics in more scenarios. We will also explore whether fine-tuning LLMs can further improve their ranking capabilities. Stay tuned!
Zhou, Chang, et al. "Predict click-through rates with deep interest network model in e-commerce advertising." 2024 5th International Conference on Information Science, Parallel and Distributed Systems (ISPDS). IEEE, 2024. ↩︎